Stworzenie stabilnej, łatwo skalowalnej architektury, która jest prosta w utrzymaniu i optymalna, jeśli chodzi i koszt utrzymania, to nielada wyzwanie. Ponieważ czasem bywa wręcz dramatycznie, my na przekór postanowiliśmy nasze zmagania z usługami AWS, Kubernetesem i innymi rozwiązaniami opisać w sposób humorystyczny.
*Disclaimer: Poniższy artykuł ma zabarwienie humorystyczne i pewne sytuacje przedstawia w krzywym zwierciadle. Nie mniej, zmagania zespołu sysops są w pełni prawdziwe.
Prolog
Spośród projektów, które realizowaliśmy, jeden szczególnie pozostał nam w pamięci, ponieważ był to nasz debiut, jeśli chodzi zbudowanie koncepcji architektury oraz utrzymanie infrastruktury dla globalnego serwisu, o trudnej do oszacowania docelowej skali. Opowiem Wam o naszych zmaganiach, wzlotach i upadkach. Momentach zwątpienia i chwały. Jak się przekonaliśmy była to niezła przygoda.
Tak to się zaczęło… A przynajmniej, tak to zapamiętaliśmy.
Scena 1: Przychodzi Klient
Klient: “Mam pomysł, będę bogaty… potrzebuję globalnego serwisu wysokiej dostępności, pozwalającego na łatwą integrację z zewnętrznymi API, bezpiecznego zarówno w warstwie programowej, jak i architektury, docelowo z wersją mobilną na IOS i Android. Tylko tyle i aż tyle. Robimy?”
inProjects Team: “Robimy! Najpierw mały research, później machniemy PoC i zobaczymy, co z tego wyjdzie.”
Na tym etapie nie ma jeszcze, żadnej niebanalnej historii w tle. Tylko pot i łzy. Wzięliśmy się do roboty. W skrócie nasze kroki wyglądały następująco:
1. Wybór języka i frameworka: bez zbędnych dyskusji padło na duet znany i lubiany: Python i Django.
2. Poszukiwanie rozwiązania do wdrożenia kluczowej funkcjonalności platformy:
-
-
- Podejście 1: HomeMadeJanuszFreeSoft – spaliliśmy trochę godzin, na poszukiwanie rozwiązania relatywnie taniego, żeby na końcu stwierdzić: “Nie działa.”
- Podejście 2: Licencjonowane rozwiązanie komercyjne – szybko trafiamy na rozwiązanie przystępne cenowo, globalne, stabilne i rozwojowe.
-
3. Przygotowanie środowiska: na nowej wirtualce wg. starego oklepanego mechanizmu stawiamy kolejno:
-
-
- venv;
- uWSGI;
- Nginx;
- lokalne środowiska wg. potrzeby na własnych komputerach;
-
4. Development PoC’a.
Scena 2: Demo PoC’a
Klient: “Biorę to! PoC jest taki, jak trzeba. A teraz działamy na poważnie. Serwis będzie globalny więc zaprojektujcie to dobrze, bo jak raz postawimy to musi stać i działać. Ma być szybko, tanio i dobrze ;-).”
inProjects Team: “Zrobimy. Będzie Pan zadowolony.”
Chociaż najpierw po cichutku, w głowach zadaliśmy sobie pytanie: “Ciekawe, jak ma na drugie imię? Może jakoś na J?
Jak do tego doszło? Do końca nie wiemy, ale okazało się, że mamy nie tylko wyprodukować oprogramowanie. Mamy je również osadzić na samodzielnie zaprojektowanej architekturze, w sposób odpowiedni dla serwisu, który ma zagwarantować wysoką dostępność usługi oraz być gotowy na przyjęcie dużego obciążenia. Oczywiście nie daliśmy po sobie tego poznać, ale był moment w którym poczuliśmy, że robi nam się nieco cieplej i bynajmniej nie była to wina źle działające klimatyzacji. Pojawiło się wyzwanie, z którym musieliśmy się zmierzyć.
Scena 3: Chwytamy byka za rogi i badamy, co to za byk
Szczęśliwie nasz zespół ma ludzi zorientowanych zarówno dewelopersko jak i devopsowo, dlatego do tematu mogliśmy podejść kompleksowo. Zaczęliśmy od zdefiniowania wymagań dotyczących infrastruktury.
Założenia:
- globalny zasięg;
- skalowalność w pionie i poziomie (teoretycznie nieograniczona);
- customizacja – możliwość podnoszenia niezależnych instancji pod konkretne wymagania klienta lub osadzanie w serwisach klientów i personalizacja aplikacji mobilnych;
- bezpieczeństwo – polityki (security groups, IAM, szyfrowanie);
- modułowość – możliwość dokładania kolejnych elementów do systemu, bez znaczącego wpływu na całość;
- prosty development i wdrażanie kolejnych releasów na produkcję;
- przewidywalne koszty;
- 99.99999999% SLA;
- asynchroniczność (także w we współpracy z zewnętrznymi API);
- backupy/monitoring;
Scena 4: Wiemy z czym się mierzymy, wiemy co musimy osiągnąć. Tylko jak?
Do określonych założeń stworzyliśmy listę możliwych rozwiązań. Po przeczytaniu całego internetu i uwzględnieniu dobrych rad zaprzyjaźnionych fachowców, pozostały nam następujące opcje:
| Zagadnienie | Opcje |
|---|---|
| Zasięg | AWS, Azure(tfu), Cloudflare, Oracle |
| Bezpieczeństwo | CDN (np: CloudFlare) |
| Koszty | możliwie najniższe, ale nie kosztem jakości |
| Skalowalność | proxy, LoadBalancing, mikroserwisy (nie wiedzieliśmy tego od razu) |
| Dostępność | HA, CDN, chmura |
| Kopie zapasowe | chmura? |
| Wdrażanie/utrzymanie | CI/CD, kontener/wirtualizacja, modułowość/mikroserwisy |
| Integracja | async, API, Celery, Redis/SQS |
| DB | Mongo, Postgres |
Jak widać, rozwiązania oparte o chmurę nas mocno kusiły. Ponieważ Microsoft ze względów ideologicznych nas zniechęcał, zaś opinie kolegów z branży na temat jakości usług w Oracle nie były pozytywne, to AWS pod względem dojrzałości produktu nie miał konkurencji. Nadal jednak mieliśmy pewne obszary na mapie do zbadania. Chodziło o integrację usług AWS, CI/CD i konteneryzację.
Scena 5: Zaczynamy prawdziwą zabawę
Początkowo nasze prace przebiegały dwutorowo. Programiści rozpoczęli pracę nad projektem i podstawową wersją serwisu, a devopsi, pod dowództwem Wasyla, nad budową stacka technologicznego. Chmura dawała nam skalowalność, dostępność i koszty za faktycznie wykorzystane usługi, a kontenery niezależność środowisk, łatwiejszy i szybszy proces wdrażania.
Względnie bezproblemowo dotarliśmy do punktu, w którym nasz produkt osadzony był w AWS na Kubernetes. No dobra… Bezproblemowo, to trochę przesadzona wersja zdarzeń 😉 Prawda jest taka, że początki były trudne, a później było tylko gorzej 😉
Na starcie bardzo chcieliśmy skorzystać ze wszystkich wodotrysków AWS, bo połknęliśmy za dużo marketingowej paplaniny. Spotkała nas za to kara…
- EKS okazał się totalnym niewypałem ze względu na sposób implementacji i ograniczenia w liczbie uruchomionych kontenerów (PODów) per serwer, jakie z tego wynikały. Postanowiliśmy, że zrobimy to po swojemu i na naszych warunkach. Nie będzie nam AWS dyktował, jak mamy klaster stawiać!
- Bjoern vs uWSGI; Bjoern skusił lekkością i szybkością działania (przynajmniej w teorii), ale kopnął nieprawidłową obsługą mediów. Decyzja: wracamy do tego, co znamy i lubimy.
Część rozwiązań okazała się jednak dla nas odpowiednia:
- RDS As A Service vs Postgres hostowany u nas. Tutaj nie było argumentów przeciwko usłudze Amazona. Mechanizmy replikacji, wysoka dostępność, święty spokój,
- EFS vs Portworx; póki co dane przechowujemy na EFS ze względu na łatwość implementacji oraz utrzymania. W niedalekiej przyszłości mamy zamiar przesiąść się na S3.
Scena 6: Spektakularny sukces

Po wielu godzinach potyczek z AWS, K8S i GitaLab, nasz stack technologiczny wyglądał mniej więcej tak:
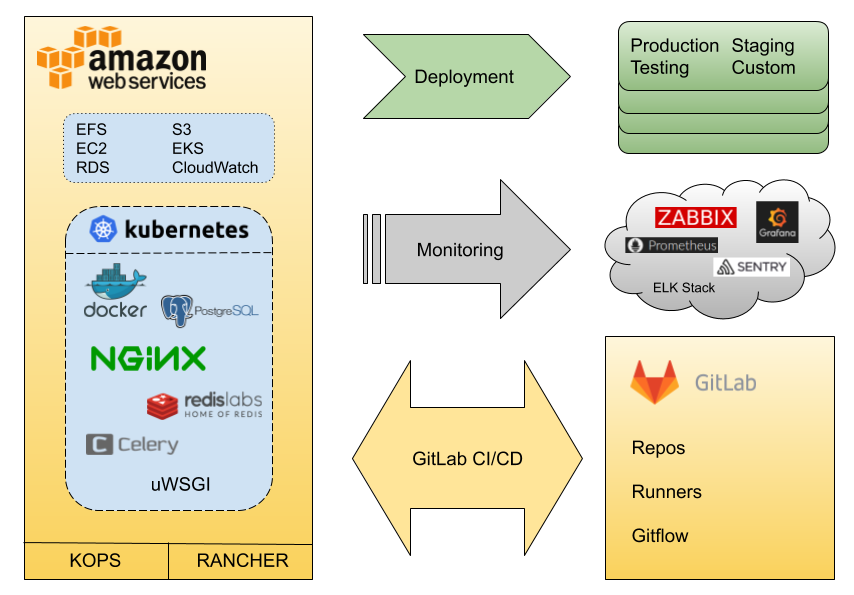
Przenaszalność stała się genialnie prosta, deweloperzy mogli za pomocą ‘docker-compose’ podnosić lokalnie w pełni funkcjonalny produkt, demo dla klienta dało się zrobić na lapku programisty albo na tymczasowej wirtualce. Deployment odbywał się całkowicie automatycznie na różne środowiska w zależności od potrzeb. W kilka minut po zmergowaniu do gałęzi RC, Testerzy (przez duże T) z zapałem i radością mogli wytykać błędy programistom. Update serwisu (pod spodem to wystawienie nowego ‘deploymentu’ w Kubernetes) generował jedynie kilkusekundową niedostępność.
Na powyższych technologicznych podstawach mogliśmy wdrożyć serwis o strukturze, która pozwalała na skalowanie i wykorzystanie wypracowanej architektury.
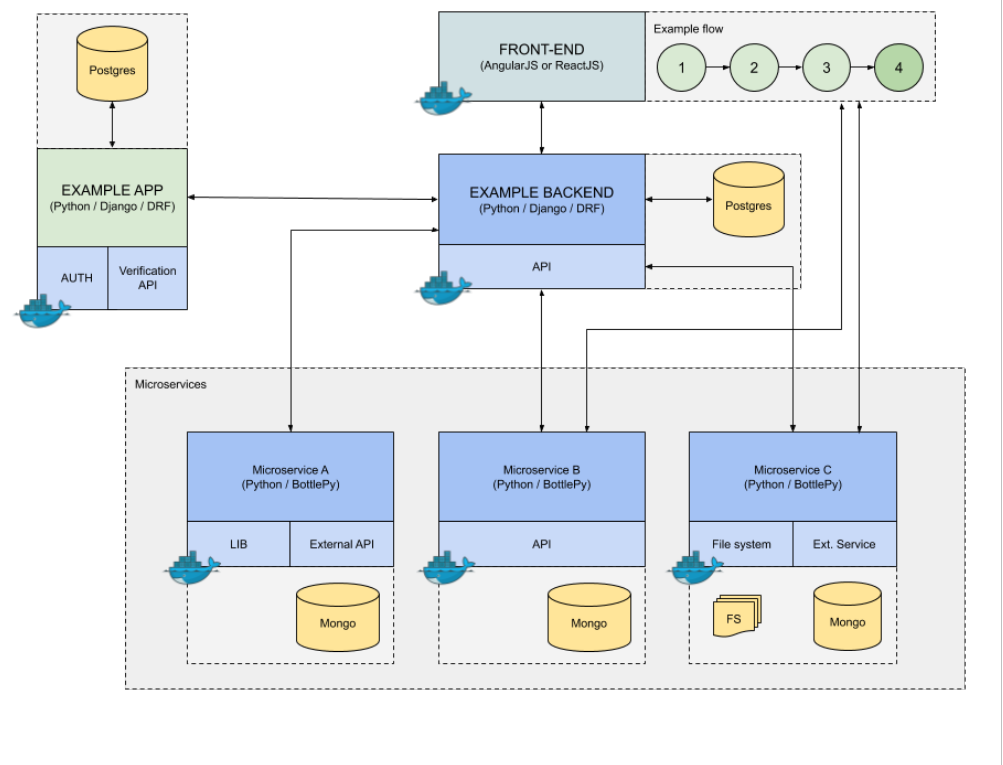 Scena 7: Mamy wszystko na oku – przed wdrożeniem produkcyjnym
Scena 7: Mamy wszystko na oku – przed wdrożeniem produkcyjnym

Zanim nasz produkt doczekał się wdrożenia produkcyjnego musieliśmy zadbać o monitoring. Programiści na bieżąco dbali o pokrycie kodu testami jednostkowymi (true story!), jednak testy integracyjne należało dopracować. Ponieważ ‘przeklikanie’ całego flow w serwisie wraz z weryfikacją spodziewanych wyników jest tożsame ze sprawdzeniem funkcjonalności wszystkich modułów (API, DB, Front) zdecydowaliśmy się wykorzystać Selenium, a wyniki jego działania zwrócić do Zabbixa. Dodatkowo do monitoringu używamy: Sentry, ELK+beats, Prometheus, Grafana.
Epilog
To był nasz pierwszy raz w takiej skali. Pierwszy raz, kiedy tak kompleksowo zmierzyliśmy się ze stworzeniem architektury o takich wymaganiach. Nie było łatwo i nie do końca przyjemnie, ale ostatecznie zdobyliśmy nowe doświadczenia i rozbudowaliśmy nasz stack technologiczny.
Na koniec kilka rad:
- nie ufajcie ślepo usługom w modelu SaaS/PaaS (np: EKS) – marketingowo wszystko wygląda pięknie, ale nie zawsze da się je dopasować do Waszych wymagań;
- uważajcie na torowisko tramwajowe w lewoskręcie jadąc na rowerze przy Mickiewicza w Szczecinie bo Wasz główny DevOps może poważnie się uszkodzić (mieliśmy przez to małe opóźnienie w dostarczeniu prac);
zmuście developerów do pisania testów wydajnościowych – będziecie mieli szansę wykryć wąskie gardła w infrastrukturze zanim zrobią to klienci;

- nie bójcie się wdrażać w dotychczas nieznane rozwiązania. Ktoś je po coś stworzył i zanim kategorycznie powiecie “nie” lepiej temat zbadać osobiście;
- monitorujcie wszystko, co tylko można, ale nie zasypujcie się alarmami, bo w końcu zaczniecie je ignorować;
- nie bójcie się prosić o rady – ludzie mają różne doświadczenia i chętnie się nimi dzielą;
My również chętnie podzielimy się naszym doświadczeniem i wiedzą zdobytą przy tym projekcie, więc jeśli nurtują Cię, jakieś pytania, odezwij się do nas.
W rzeczywistości jesteśmy dużo sympatyczniejsi i cywilizowani niż może to wynikać z tego wpisu 😉
Zdjęcie: link
Diagram: link
AWS: link
AWS 2: link
Mem Unit Tests: link
Zdjęcie rower: link