Creating a stable, easily scalable architecture that is easy to maintain and optimal in terms of cost and maintenance is a challenge. Sometimes it is even dramatic, so we decided to describe our struggles with AWS, Kubernets and other solutions in a humorous way.
Prologue
Through all projects, which we have fulfilled, there is one that has a special place in our memories. It was our debut in creating an architecture concept and maintaining the infrastructure for global service in a difficult to estimate target scale. I will tell you about our struggles, ups, and downs, as well as moments of doubt and glory. As we have seen, it was quite an adventure.
Disclaimer: The presented article is humorous and certain situations are shown as a grotesque. Nevertheless, the DevOps’ struggles are completely true.
It all started from…. At least, that’s how we remembered it.
Stage 1: The customer comes
Customer: “I have an idea, and I will be rich… I need a global service with high availability, which allows easy integration with external API and secured in both program and architecture layout. It should have ultimately a mobile version for IOS and Android. It’s no more and no less. Shall we do it?”
InProjects Team: “Let’s do it! We will start with a small research and afterward, we will pop a PoC (Proof of Concept) and see what will come from it.”
At this stage, there is no unique story behind it, only sweat and tears. We all get to work. In short our work derived into the following stages:
1. Choosing language and framework: without any discussions, we choose a known and liked duo: Python and Django.
2. Searching for solutions to implement platforms’ key functionality:
-
-
- First approach: “HomeMadeFreeSoft” – we wasted some hours looking for a relatively cheap solution, which gave us a conclusion: “It doesn’t work.”
- Second approach: Licensed commercial solutions – we quickly find a solution that is affordable, global, stable and developmental.
-
3. Preparing the environment: with use of the new virtual system and old well-worn mechanism we settle successively:
-
-
- venv;
- uWSGI;
- Nginx;
- local environments according to the needs of own computers;
-
4. Development of PoC.
Stage 2: Demo version of PoC
Customer: “I take it! PoC is as it should be. And now it is time to work seriously. Service will be a global one, so you need to design it well. Once it will be established it needs to operate. It should be done fast, cheap and good 😉”
inProjects Team: We will do it. You will be pleased with it.”
How did this happen? We are not fully sure about that, but it turned out that we are supposed to not only create software but we also need to embed it on self-designed architecture in an adequate way to service requirements which will guarantee high availability of services and will be prepared for acceptation of a heavy burden. Of course, we did not show it, but there was a moment when things got a little heated, and it was not a bad working air conditioner. This was a great challenge and we needed to face it.
Stage 3: We bite on the bullet, and we explore what this bullet is…
Luckily, our team consists of people that have not only developers but also DevOps experience. This allowed us to deal with it comprehensively. We started by stating the infrastructure’s requirements.
Assumptions:
- global reach;
- vertical and horizontal scaling (theoretical unlimited scalability);
- customizing – the availability of lifting independent instances for particular customer’s requirements or embedding it in customer websites with personalization of mobile applications;
- safety – policies (security groups, IAM, encrypting);
- modularity – the possibility of adding further elements to the system without a significant impact on the whole;
- simple development and implementing additional releases on production;
- predictable costs;
- SLA on 99.99999999% level;
- the asynchronicity (in cooperation with external API as well);
- backups and monitoring;
Stage 4: We know what is our challenge, and we know what we need to achieve. But how to do it?
We prepared the list of available solutions for our determined assumptions. After reading the whole Internet and including good advice from our befriended specialists we came with the following options:
| Issue | Options |
|---|---|
| Reach | AWS, Azure(tfu), Cloudflare, Oracle |
| Safety | CDN (ex.: CloudFlare) |
| Costs | Possibly the lowest, but not at the expense of quality |
| Scaling | proxy, LoadBalancing, microservices (we didn’t know this immediately) |
| Availability | HA, CDN, cloud |
| Backup | cloud? |
| Implementation / maintaining | CI/CD, container / virtualization, modularity/ microservices |
| Integration | async, API, Celery, Redis/SQS |
| DB (data base) | Mongo, Postgres |
As you can see the solutions based on the cloud were tempting us. Since Microsoft was discouraging from the ideological considerations for us, and our branch friends shared negative opinions about service quality in Oracle, that AWS in a matter of fact has had no competition in the maturity stage of a product. We still had on our map some areas to explore more. Mostly is was about the integration of AWS services, CI/CD and containerization.
Stage 5: The real fun begins.
In the beginning, our work proceeded on two tracks. Developers started their work on the project and basic version of the site, DevOps specialist under the leadership of Wasyl started the construction of technological stack. The cloud has given us the scaling, availability, and costs for only used services, containers, on the other hand, allowed the independence of the environments, easier and faster implementation process.
Relatively seamlessly we reached the point where our product was embed in AWS on Kubernetes. All right…. Maybe seamlessly word is an exaggeration in this event version 😉. The truth is that the beginnings were very hard, and later it was even worse 😊.
When we began we wanted to use all AWS sources, as we consume too much marketing talk. We were punished for that…
- EKS turned out to be a total non-event because of the way of its implementation and limitations in some running containers (pods) via server. We decided to do it on our own and in our style and conditions. No AWS will tell us how we should settle a cluster!
- Bjoern vs uWSGI; Bjoern seemed to be light and fast in operating (basically in theory), but it came with difunctional use of media. Decision: we came back to the solution we know and like.
Part of solutions turned down to be suitable for us:
- RDS As A Service vs Postgres hosted by us. We did not have any arguments against Amazon’s service. Replication mechanisms, high availability, peace, and quiet,
- EFS vs Portworx; We keep data on EFS for now because of the easy implementation and maintaining. In the nearest future, we have a plan to relocate on S3 service.
Stage 6: The spectacular success

After many hours of struggles with AWS, K8S and GitaLab our technological stack was looking more or less like this:
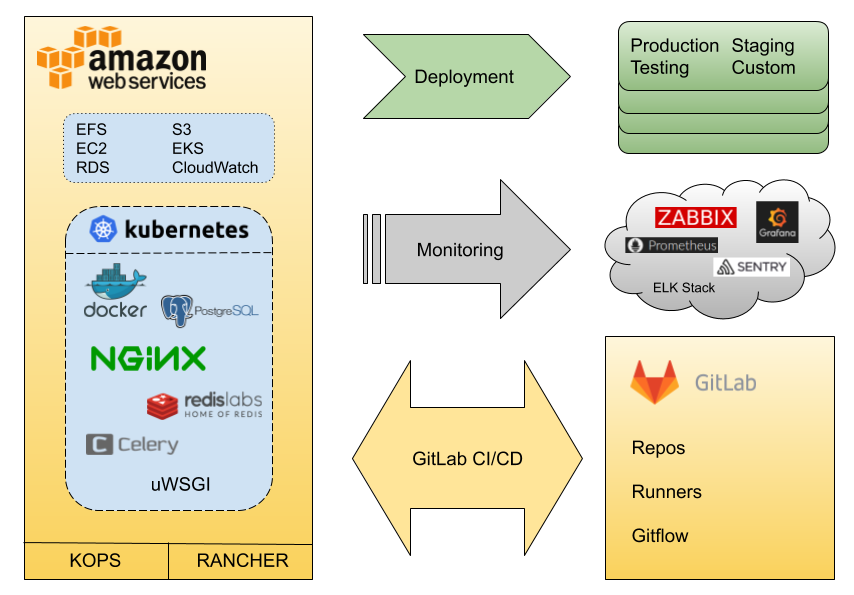
Portability has become brilliantly simple. With the use of ‘docker-compose’ developers could raise a fully functional product locally, the demo version for the customer was possible to do on the programmer’s notebook or on a temporary virtual machine. Deployment took place fully automatically in different environments and depending on needs. In a few minutes after merging to the RC branch, Testers (with a capital letter) were happily and eagerly able to point out mistakes to programmers. Service update generated only a few seconds of unavailability (underneath it was putting a new ‘deployment’ to Kubernetes).
On the above technological basis, we could implement service in a structure, which allowed scaling and using developed structure.
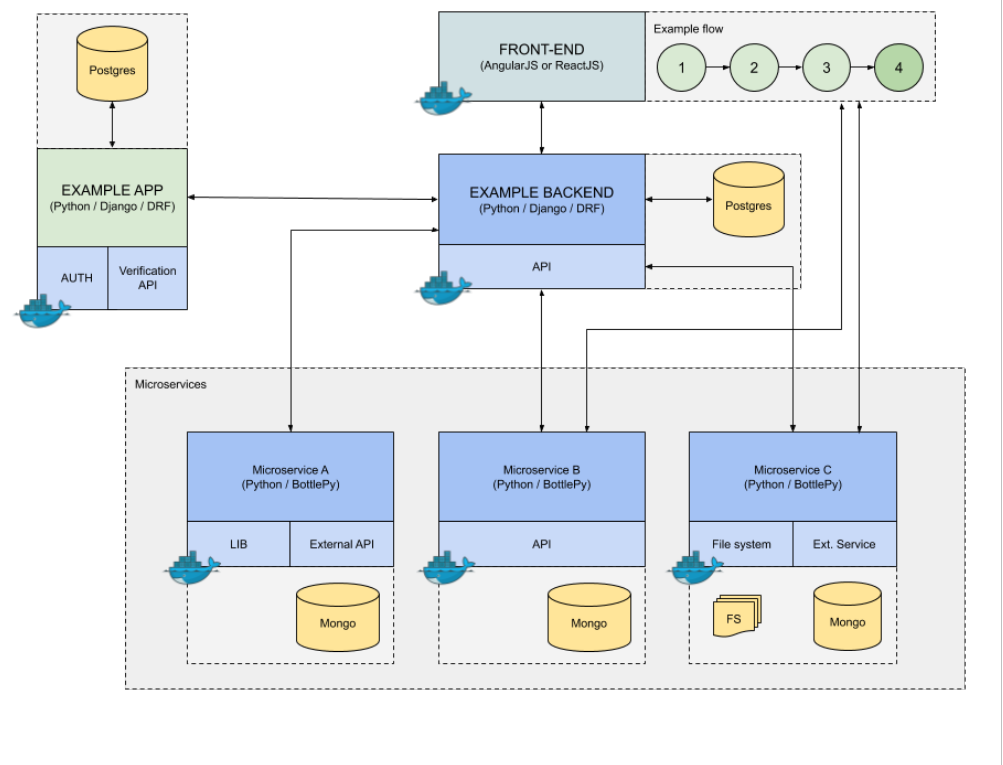
Stage 7: We keep an eye on everything – before implementation to the production environment

Before the implementation of our product to the production environment we need to focus on monitoring. Programmers took care of covering code with unit tests (true story!), but integration tests still needed to be refined. As far as clicking through all flow on-site together with verification of expected scores is synonymous with checking the functionalities of all modules (API, DB, Front), we decided to use Selenium, and scores which we received from its work we put to Zabbix. Additionally, during the monitoring process, we use Sentry, ELK+beats, Prometheus, Grafana.
Epilogue
This was our first time with this scale of the project. For the first time, our team has comprehensively faced the challenge of building architecture with this kind of requirement. It was not easy and not a pleasant task completely, but all in all, we gain new experience and we build our technological stack.
We have some advice as a conclusion:
- do not trust blindly services in Saas/Paas models (ex.EKS) – from the marketing point of view all is looking perfect but it is not always possible to adapt it to your requirements;
- watch out for the tram track in the left turn when cycling by Mickiewicza in Szczecin because your main DevOps specialist can hurt itself (we had a small delay in work because of that)
- make developers write performance tests – you will have a chance to detect bottleneck in the infrastructure before your customers will;

- do not be afraid to introduce yourself with new solutions. Somebody has created it for something and before you say categorically “no” explore it personally;
- monitor everything that you can but do not overwhelm yourself wit alerts, because you will finally ignore them;
- do not be afraid to ask for a piece of advice – people have a different experience and they share it willingly;
We will be also happy to share our experience and knowledge gained in this project, so if you are bothering with any questions, please contact us.
In fact, we are much more friendly and civilized than it can appear from this post 😉
Picture: link
Diagram: link
AWS: link
AWS 2: link
Mem Unit Tests: link
Photo of a bicycle: link